
Descargar datos:
El dataset para entrenar los datos: dataset_train_absentismo
El dataset para hacer las predicciones finales (de aquí se saca el resultado del desafío): dataset_test_absentismo
Datos proporcionados:
El conjunto de datos contiene 740 registros de empleados con 21 variables, incluyendo la variable objetivo (Absenteeism) que indica el tiempo de absentismo en horas. Para este reto, hemos convertido esta variable en binaria
- Clase 0: No hubo absentismo (tiempo de absentismo = 0 horas).
- Clase 1: Hubo absentismo (tiempo de absentismo > 0 horas).
| Nombre de variable | Descripción |
| ID | Identificador único del empleado |
| Reason for absence | Ausencias documentadas por el Código Internacional de Enfermedades (CID), divididas en 21 categorías (I a XXI), que incluyen:
|
| Month of absence | Mes de la ausencia |
| Day of the week | Día de la semana (Lunes (2), Martes (3), Miércoles (4), Jueves (5), Viernes (6)). |
| Seasons | Estación del año |
| Transportation expense | Gasto en transporte |
| Distance from Residence to Work | Distancia desde la residencia al trabajo (en km) |
| Service time | Tiempo de servicio (en años) |
| Age | Edad del empleado |
| Work load Average/day | Promedio de carga de trabajo por día |
| Hit target | Objetivo alcanzado (en porcentaje) |
| Disciplinary failure | Fallo disciplinario (0: No, 1: Sí) |
| Education | Nivel educativo (secundaria (1), graduado (2), postgrado (3), maestría y doctorado (4)). |
| Son | Número de hijos |
| Social drinker | Bebedor social (0: No, 1: Sí) |
| Social smoker | Fumador social (0: No, 1: Sí) |
| Pet | Número de mascotas |
| Weight | Peso (en kg) |
| Height | Altura (en cm) |
| Body mass index | Índice de masa corporal |
| Absenteeism | Absentismo (0: No, 1: Sí) |
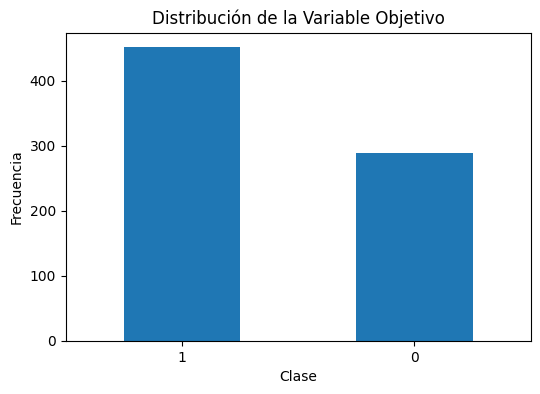
Distribución de la variable objetivo: Absenteeism
Clase 0: 451
Clase 1: 289
Nuestro compromiso con el sesgo en los datos
Una de las variables disponibles en este datase es Body mass index, índice de masa corporal en castellano.
El índice de masa corporal (IMC) es una métrica que ha sido utilizada durante mucho tiempo para estimar la salud de una persona basándose en su peso y altura. El IMC se calcula dividiendo el peso de una persona en kilogramos por el cuadrado de su altura en metros (kg/m²).
Aunque el IMC es fácil de calcular y puede proporcionar una indicación general del riesgo de problemas de salud relacionados con el peso, tiene varias limitaciones que han sido objeto de críticas:
- No distingue entre masa grasa y masa muscular: El IMC no diferencia entre el peso de los músculos y el peso de la grasa. Por lo tanto, personas con una alta masa muscular pueden ser clasificadas erróneamente como obesas o con sobrepeso [1][2].
- No considera la distribución de la grasa corporal: El IMC no proporciona información sobre dónde se almacena la grasa en el cuerpo. La grasa abdominal, por ejemplo, está asociada con un mayor riesgo de enfermedades cardiovasculares, pero esto no se refleja en el IMC [1][2].
- Variabilidad entre diferentes grupos de personas: El IMC puede no ser igualmente aplicable a todas las poblaciones. Factores como la edad, el sexo y la composición corporal pueden influir en la precisión del IMC como indicador de salud [1][2].
- Uso potencialmente discriminativo: Basarse únicamente en el IMC para evaluar la salud de una persona puede conducir a discriminación y estigmatización, especialmente en contextos laborales y de seguros de salud. Puede llevar a juicios rápidos y simplistas sobre la salud de una persona sin considerar otros factores importantes [1][2].
Por estas razones, muchos expertos en salud y organizaciones han comenzado a considerar el IMC como una herramienta limitada y, en algunos casos, inadecuada para evaluar la salud individual. Se están promoviendo enfoques más holísticos que tengan en cuenta una variedad de factores, como la dieta, la actividad física, la distribución de la grasa corporal, y otros indicadores de salud metabólica.
Referencias:
[1] Humphreys S. (2010). The unethical use of BMI in contemporary general practice. The British journal of general practice : the journal of the Royal College of General Practitioners, 60(578), 696–697. https://doi.org/10.3399/bjgp10X515548
[2] Austin, S. B., & Richmond, T. K. (2022, October 19). It’s time to retire BMI as a clinical metric: An undue focus on weight can lead to patient distrust and delayed care. https://www.medpagetoday.com/opinion/second-opinions/101296
El objetivo de este reto es desarrollar un modelo predictivo que pueda estimar si un empleado se ausentará o no en su trabajo usando el dataset proporcionado.
- Analiza bien la información
- Genera un modelo predictivo y entrénalo
- Obtén resultados y evalúalos
⚠️⚠️¡Este reto tiene PREMIO! Si tu solución es la mejor te llevaras una tarjeta de regalo de 100€ en Amazon ⚠️⚠️
El dataset utilizado presenta clases no balanceadas, por lo que se utilizará el área bajo la curva (AUC) como métrica principal de evaluación del rendimiento del clasificador. Esta métrica es adecuada para evaluar modelos en situaciones donde hay desigualdad significativa entre las frecuencias de clases.
La métrica de evaluación utilizada para el clusterig será Silhouette Score. Es una métrica que ofrece una visión clara y comprensible de la calidad del clustering, permitiendo interpretar fácilmente si los clústeres están bien formados y si los puntos están correctamente agrupados.
Además, se puede usar la herramienta SHAP (SHapley Additive exPlanations) para proporcionar explicaciones sobre las decisiones del clasificador. SHAP permitirá analizar tanto a nivel global como local cómo cada característica afecta las predicciones del modelo, proporcionando una comprensión detallada de los factores determinantes en las predicciones y cómo estas se ven afectadas por diferentes variables.
⚠️IMPORTANTE⚠️ Este reto tiene PREMIO, si tu solución es la mejor te llevaras una tarjeta de regalo de 100€ en Amazon
Formato de entrega
- Predicción:
-
- Un archivo csv con una sola columna.
-
-
- Nombre de la columna: target
-
-
-
- Contenido de la columna: predicciones de las etiquetas del dataset test.
-
-
-
- ¡IMPORTANTE! El orden de la columna debe ser el mismo orden del dataset test dado en el enunciado.
-
-
- Ejemplo visual del csv
| target |
| 1 |
| 0 |
| … |
- Clusterización:
-
- Un documento que contenga:
-
- Descripción de los clústeres: Una descripción detallada de cada clúster, incluyendo las características promedio de los empleados en cada clúster.
-
- Justificación del número de clústeres: Explicación sobre cómo se decidió el número de clústeres (técnica utilizada…).
-
- Un archivo csv con tres columnas.
-
-
- Primeras dos columnas
-
-
-
-
- Nombre de la columna 1: id
-
-
-
-
-
- Nombre de la columna 2: cluster
-
-
-
-
-
- Contenido: id del empleado y el cluster que se le ha asignado .
-
-
-
-
- Tercera columna
-
-
-
-
- Nombre de la columna 3: total
-
-
-
-
-
- El número de clusters totales
-
-
-
- Ejemplo visual del csv
| id | cluster | total |
| 1 | 4 | 7 |
| 2 | 6 | |
| … | … |
- Gráficos de barras o de dispersión (opcional): Si se utiliza SHAP, hace falta entregar uno o varios gráficos que muestren los valores SHAP (SHapley Additive exPlanations) para cada una de las variables predictoras principales del modelo. Estos gráficos son útiles para visualizar cómo cada variable contribuye a las predicciones del modelo de manera individual y le proporcionan robustez a la solución.
🎉🎉El ganador de este reto ha sido Dpolob. ¡¡¡Felicidades!!! 🎉🎉