
Datasets
- Dataset de entrenamiento: train_set_ctr.csv
- Dataset de prueba: test_set_ctr.csv
El conjunto de datos incluye variables como el tiempo que pasa un usuario en el sitio, la edad, el ingreso del área, entre otros, que pueden influir en la probabilidad de clics en un anuncio.
Variables del dataset
En total hay 10 columnas: 9 variables y la clase o variable objetivo.
- Daily Time Spent on Site: Tiempo diario que un usuario pasa en el sitio (en minutos).
- Age: Edad del usuario.
- Area Income: Ingreso promedio del área del usuario.
- Daily Internet Usage: Uso diario de Internet por el usuario (en minutos).
- Ad Topic Line: Línea de tema del anuncio.
- City: Ciudad del usuario.
- Sexo: Sexo del usuario.
- Country: País del usuario.
- Timestamp: Marca de tiempo de cuando se registró el clic en el anuncio.
- Clicked on Ad: Variable objetivo, binaria (0: No hizo clic, 1: Hizo clic).
El desafío consiste en desarrollar un modelo de clasificación binaria que prediga si un usuario hará clic en un anuncio. Además de construir un modelo de clasificación binaria, se valorará de forma muy positiva utilizar SHAP (SHapley Additive exPlanations) para proporcionar explicaciones sobre las decisiones del modelo. Como sabemos que se trata de una herramienta que actualmente está empezando a conocerse tenemos un post para explicando cómo funciona, ejemplos de código incluidos.
Métrica de evaluación
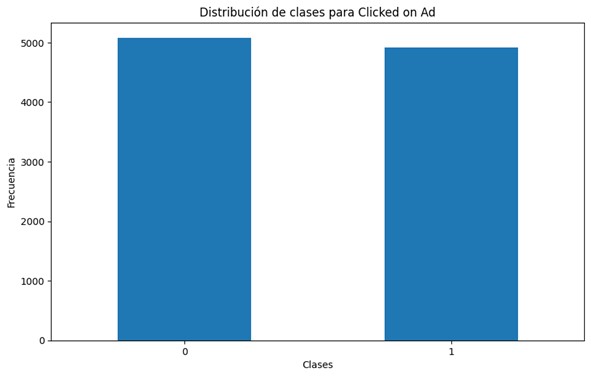
Dado que el dataset muestra clases balanceadas, se evaluará el resultado con una de las métricas más robustas en este escenario, la tasa de acierto o accuracy. Además, se puede emplear la herramienta SHAP (SHapley Additive exPlanations) para proporcionar explicaciones sobre las decisiones del modelo. SHAP permitirá analizar cómo cada característica influye en las predicciones del modelo, tanto a nivel global como local.
Formato de entrega
- Un archivo csv con una sola columna.
- Nombre de la columna: target
- Contenido de la columna: predicciones de las etiquetas del dataset test.
- ¡IMPORTANTE! El orden de la columna debe ser el mismo orden del dataset test dado en el enunciado.
- Ejemplo visual del csv
| target |
| 1 |
| 0 |
| … |
- Gráficos de barras o de dispersión (opcional): Si se utiliza la herramienta SHAP, hace falta entregar uno o varios gráficos que muestren los valores SHAP (SHapley Additive exPlanations) para cada una de las variables predictoras principales del modelo. Estos gráficos son útiles para visualizar cómo cada variable contribuye a las predicciones del modelo de manera individual y le proporcionan robustez a la solución.