Predicción del tráfico a la entrada de un Polígono Industrial Vasco
La entrada al Polígono Industrial de este reto tiene un tráfico elevado. Miles de vehículos se desplazan a diario a esa zona de la ciudad para realizar su trabajo. Esto se agrava a determinadas horas del día, donde el flujo de vehículos es más alto. Si a esto le sumamos que se trata de un …
La entrada al Polígono Industrial de este reto tiene un tráfico elevado. Miles de vehículos se desplazan a diario a esa zona de la ciudad para realizar su trabajo. Esto se agrava a determinadas horas del día, donde el flujo de vehículos es más alto. Si a esto le sumamos que se trata de un entorno industrial, donde se mueven grandes cantidades de camiones de transporte, y que debido a la turnicidad, la afluencia de vehículos es elevada en muchos momentos del día, el estudio de estos momentos pico del día, resulta complejo.
La ciudad quiere establecer medidas que permitan favorecer el tráfico, evitar los accidentes y los atascos, además de reducir la contaminación. Para ello, se ha instalado a la entrada del polígono un sistema de visión que ha capturado durante un mes (31 días exactamente) la tipología de vehículos que han accedido al polígono. Estos datos se tomaron en franjas de 15 minutos. Con esta información capturada, la ciudad ha estudiado si la afluencia de vehículos es muy elevada, y han clasificado el tráfico como muy alto, alto, normal o bajo.
Pero este estudio no termina aquí: con esta información la ciudad quiere establecer un modelo predictivo a través del cual, puedan predecir para determinados momentos del día y la semana, si el tráfico en el polígono será elevado, y establecer políticas que mejoren los accesos y el tránsito en estas zonas. Y es aquí donde comienza tu labor: mediante los datos de train que encontrarás en el apartado de “Datos”, deberás:
En este reto se pide estudiar las condiciones del tráfico, con información recopilada gracias a un sistema de visión. El sistema detecta cuatro clases de vehículos a la entrada de un polígono industrial al que acceden trabajadores a diario:
Automóviles (vehículos utilitarios)
Bicicletas
Autobuses
Camiones
El conjunto de datos se almacena en un archivo CSV e incluye columnas que dan información adicional, y que puede ser necesaria para el modelo que desarrolles:
Horas (con información actualizada en bloques de 15 minutos)
Fecha (el número del día del mes, ya que el estudio está hecho en un mes completo de 31 días)
Días de la semana (de lunes a domingo)
Recuentos para cada tipo de vehículo (CarCount, BikeCount, BusCount, TruckCount).
La columna “Total” representa el recuento total de todos los tipos de vehículos detectados en un período de 15 minutos.
El conjunto de datos se actualiza cada 15 minutos, lo que proporciona una visión completa de los patrones de tráfico a lo largo de un mes completo (31 días). Además, el conjunto de datos incluye una columna que indica la situación del tráfico categorizada en cuatro clases:
1-Heavy: tráfico denso y con propensión a atascos
2-High: alto, con altas probabilidades de atascos
3-Normal: tráfico normal, sin incidencias reseñables
4-Low: bajo, con muy baja probabilidad de incidencias.
Esta información te debe ayudar a evaluar la gravedad de la congestión y a monitorizar las condiciones del tráfico en diferentes momentos y días de la semana.
Contarás con dos bases de datos para elaborar un modelo de clasificación basado en datos etiquetados:
train_datos trafico.csv: Esta base de datos completa y clasificada, con 2380 registros, te permitirá entrenar tu modelo. Comienza realizando un análisis descriptivo de la información, identifica las variables que son realmente significativas en tu análisis y entrena tu modelo.
test_datos trafico.csv: Te proporcionamos además la base de datos de test, la cual, una vez tengas tu algoritmo listo, deberás utilizar para obtener los resultados de 596 registros, a los que tu modelo asignará la clasificación de la tipología de tráfico para cada registro.
Mediante los datos de train que encontrarás en el apartado de “Datos”, deberás:
Analizar la información facilitada en el apartado de “Datos” y estudiar la calidad de la información recopilada por el sistema de visión a la entrada del polígono.
A través de los datos de entrenamiento (train) desarrollar un modelo predictivo de clasificación que, en función de las variables de estudio que consideres más importantes, determine si el tráfico es muy denso, alto, normal o bajo (de acuerdo a la clasificación que encontrarás en el apartado “Datos”)
Una vez tengas el modelo entrenado, con los datos de test, podrás aplicar en ellos la lógica de tu modelo, y obtener la clasificación para esos datos no etiquetados. Ese resultado será el que deberás subir a Kopuru, para que podamos evaluar tu porcentaje de acierto, junto con el código de tu solución.
¿Quieres deslumbrar? Si además crees que de tu análisis puede obtenerse más información, adjunta un PDF donde nos cuentes: por qué tu solución es la mejor, y que ideas se te ocurren para aplicar soluciones que mejoren el tráfico, basado en las conclusiones que has obtenido al entrenar tu modelo. Nos encantará ver soluciones que además, aporten un valor a problemas reales.
Evaluar el modelo de clasificación será sencillo a través del archivo de test que te proporcionamos en el apartado de “Datos”. Para ello, deberás:
Entrenar tu modelo con los datos de entrenamiento (train), habiendo identificado las variables que consideras representativas y que afectan al modelo.
Utiliza el archivo de Test para aplicar la clasificación a los 596 datos no etiquetados que encontrarás en este archivo. Si tu entrenamiento ha sido bueno, estamos seguros de que conseguirás un modelo con un porcentaje de acierto altísimo.
Deberás subir a Kopuru en un ZIP la siguiente información:
CSV de los resultados aplicando el modelo desarrollado a los datos de test. Guarda el CSV con el nombre “TraficoDataEvaluado_TU NOMBRE_v01.csv”. Si quieres subir una nueva versión porque has conseguido mejorar tu resultado, recuerda subirlo de nuevo, pero indicando que se trata de una versión distinta en el nombre: “TraficoDataEvaluado_TU NOMBRE_v02.csv”
Archivo con el código desarrollado, en un “.py” por ejemplo. Este no se utilizará para la evaluación, pero si para comprobar que realmente has desarrollado el código desde cero en caso de resultar ganador, o para subirlo a la plataforma y que puedas compartirlo con el resto de usuarios.
Esta parte es opcional, pero deseable, y es que nos encantará que adjuntes un PDF donde expliques por qué tu solución es la mejor, qué solución has elegido y por qué, y sobre todo, que nos expliques qué conclusiones has obtenido y cómo pueden trasladarse a medias reales que ayuden a minimizar el tráfico en este acceso.
Evaluaremos todas las soluciones subidas antes de la fecha de cierre del reto, por lo tanto, estate atento y no dejes pasar la fecha. Recuerda que puedes subir tantas soluciones como consideres para mejorar tu modelo, ya que en este caso las evaluaremos todas.
Cuando tengamos los resultados, los subiremos en el apartado de “Resultados”, donde podrás ver el ranking de posición obtenido frente al resto de participantes. Aparecerás con tu nombre y la inicial de tu apellido en dicho ranking.
Una vez finalizado el plazo de entrega, y cuando llegue la fecha de publicación de resultados, publicaremos los datos completos y el ranking, donde podrás ver en qué posición has quedado y su has sido el vencedor. Esta vez el premio son unos cascos inalámbricos Xiaomi Redmi Buds 4 con cancelación de ruido.
Recuerda que para participar, debes tener claros los siguientes puntos:
Para participar en un reto es indispensable registrarse en Kopuru como miembro de la comunidad. Esto podrás realizarlo directamente en nuestro apartado de perfil.
Es indispensable leer las bases antes de hacer la entrega, de cara a cumplir con los requisitos antes de hacer cualquier entrega, y asegurar que esta pueda ser evaluada.
Los datos de entrenamiento (train) son los que debes utilizar para entrenar tu modelo. Identifica las variables necesarias y haz un análisis previo de la información para evaluar la calidad de los datos. A modo de consejo, te recomendamos que antes de hacer un borrado de registres, valores si las variables afectan realmente o no a tu modelo (no pierdas información importante por el camino).
Los datos de test son datos limpios y el csv resultado debe contener los 596 registros que aparecen en el csv, con su clasificación de tipo de tráfico aplicada gracias a tu modelo. Si en la subida de datos identificamos que esta información no está completa, enviaremos un aviso a los participantes avisando de que su CSV de resultado no está completo.
Es indispensable subir en un ZIP los dos archivos principales: el CSV con los resultados etiquetados, y el archivo con el código. El primero será el que Kopuru evalúe, y el segundo, el que se revisará en caso de ser ganador, para validar la solución. A modo opcional, añadir un PFD con las conclusiones y explicaciones solicitadas en el apartado de descripción del reto, se valorará muy positivamente, sobre todo en caso de empates.
Si el ZIP entregado no contiene uno de los dos archivos principales (el CSV de resultados o el archivo de código), esta entrega no podrá ser evaluada, y figurará como entrega no presentada. Es responsabilidad del participante leer atentamente este apartado y cumplir con las especificaciones solicitadas.
Si tras haberse inscrito en el reto, se decide no seguir con la participación, se pide a los participantes que anulen su suscripción, de manera que quede constancia de que su resultado no va a ser subido, y podamos ceder esa plaza a otro participante interesado.
El ganador del reto y el ranking de resultados se publicarán el día de publicación de resultados, indicado en la información del reto. Se contactará directamente con el ganador para hacerle llegar el premio.
Ante cualquier duda que surja en la resolución del reto, puedes contactar con nosotros a través de info@kopuru.com
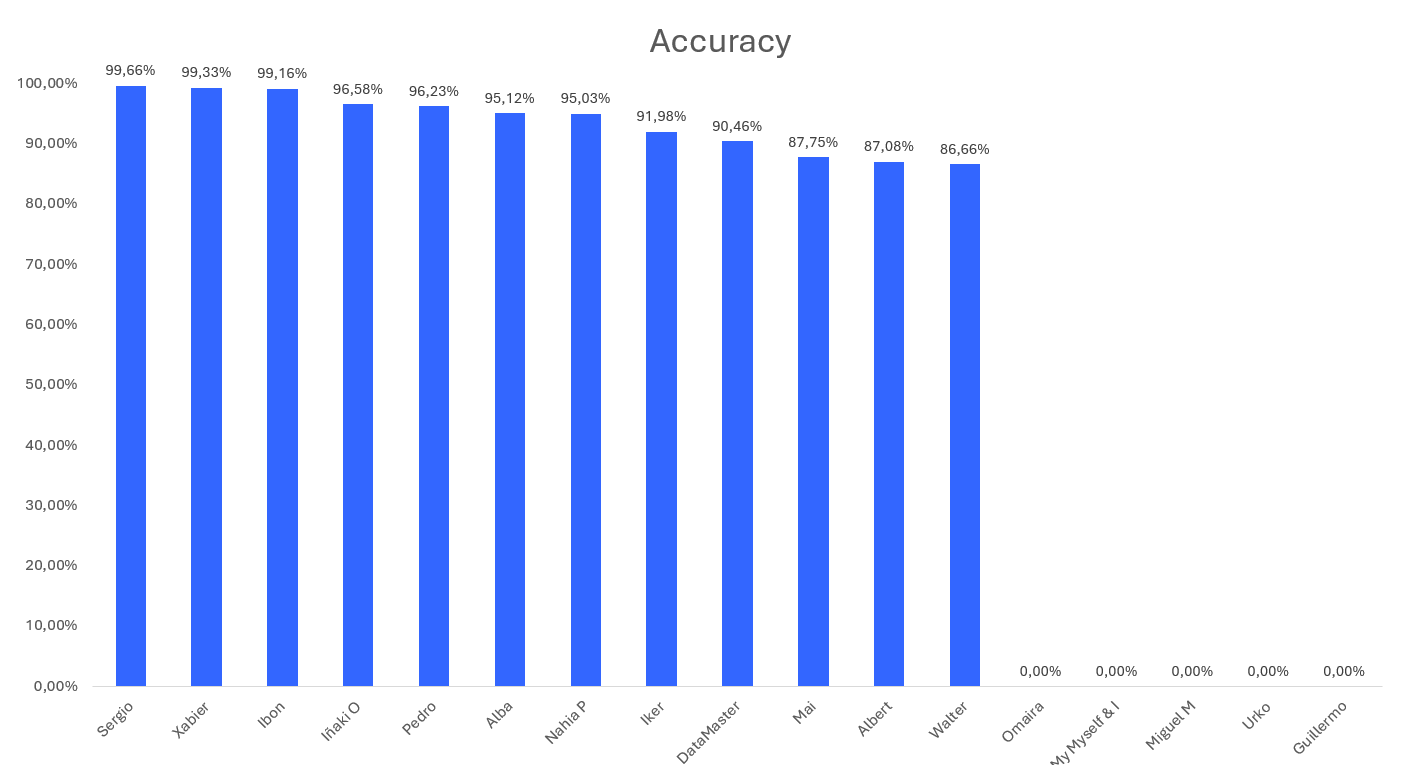
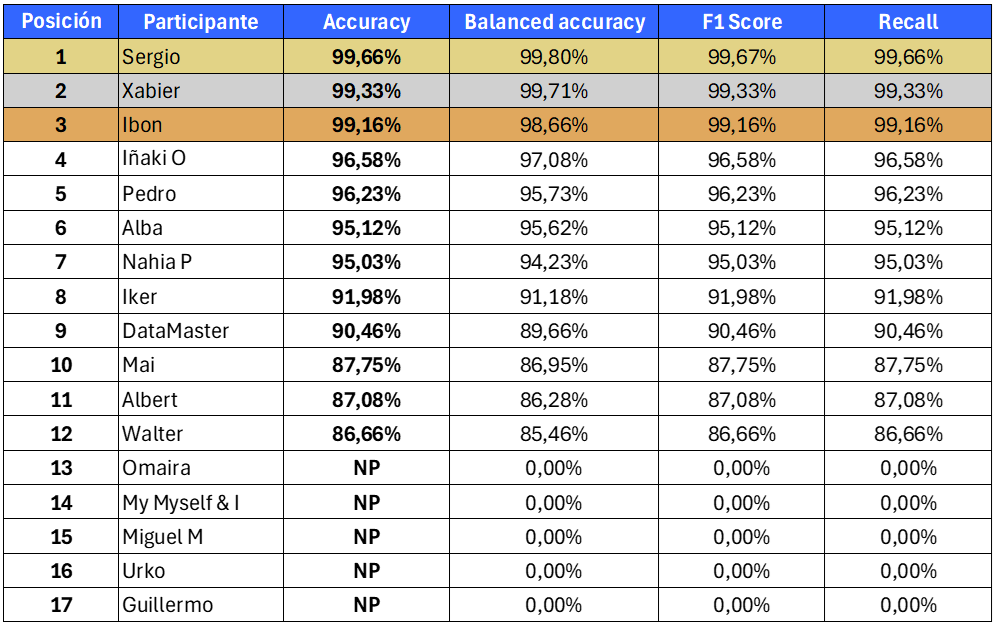
Estos son los resultados del reto sobre predicción del tráfico. Felicidades a todos los participantes y al ganador!
El premio son unos cascos inalámbricos Xiaomi Redmi Buds 4 con cancelación de ruido.
Gestionar el consentimiento de las cookies
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu Proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.