¿Sabías que detrás de las innovaciones tecnológicas que nos rodean el día a día, como un asistente virtual, los vehículos autónomos y los sistemas de recomendación, se esconden los algoritmos de machine learning? La presencia de vehículos que circulan sin necesidad de un conductor, los asistentes virtuales que pueden responder a nuestras preguntas con precisión y las recomendaciones personalizadas, van camino de convertirse en un elemento de nuestro día a día. Pero para llegar a ello, los algoritmos de inteligencia artificial son fundamentales para que las máquinas aprendan y tomen decisiones por sí mismas. En este artículo, vamos a explorar los principales algoritmos de machine learning que están cambiando nuestro mundo, y que podrían ayudarte. ¡No te lo pierdas!
Imagina por un momento que el conocimiento infinito estuviera a tu alcance. A esto súmale la capacidad de aprender y mejorar constantemente sin intervención humana. En eso consiste precisamente el machine learning. Estos algoritmos son el corazón de la inteligencia artificial y están diseñados para aprender de los datos, identificar patrones y tomar decisiones precisas sin una programación explícita. En pocas palabras, los algoritmos de machine learning permiten a las máquinas aprender y evolucionar por sí mismas.
Explorando los algoritmos de machine learning
Vale, ahora profundicemos en algunos de los algoritmos de machine learning más utilizados en la actualidad. Estos algoritmos se basan en diferentes enfoques y técnicas, pero todos comparten el objetivo común de permitir que las máquinas aprendan y tomen decisiones de manera autónoma.
Los algoritmos de aprendizaje automático se segmentan en tres tipos:
Aprendizaje Supervisado
Aprendizaje No Supervisado
Aprendizaje de Refuerzo
Árboles de decisión
Los árboles de decisión son estructuras en forma fractal que muestran una secuencia de decisiones y sus posibles resultados. Cada punto de encuentro en el árbol representa una pregunta o una condición, y las ramas representan las posibles respuestas o resultados. Siguiendo el camino desde la raíz hasta las hojas del árbol, se llega a una decisión final.
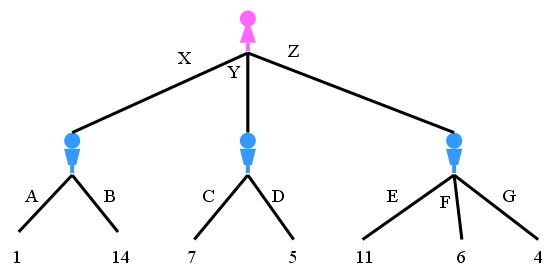
La construcción de un árbol de decisión se basa en la selección de las preguntas o condiciones más relevantes en cada situación. El fin es la toma de decisiones de la forma más inteligente, maximizando la precisión y el acierto y minimizando la duda. Para lograrlo, se utilizan algoritmos que analizan el conjunto de datos y seleccionan las características más informativas en cada nodo.
Los árboles de decisión se aplican en muchos campos. En las empresas, se utilizan para la toma de decisiones estratégicas, como la segmentación de clientes y la predicción de ventas. En medicina, los árboles de decisión se utilizan para el diagnóstico de enfermedades y determinar los tratamientos más adecuados. Además, se aplican en sistemas de recomendación, rastreo de fraudes y en muchos más campos.
Clasificación Näive Bayes
El clasificador Naïve Bayes se basa en el teorema de Bayes, una fórmula matemática que permite hayar la probabilidad de que se dé un evento en concreto según un conjunto de evidencias. En el contexto de la clasificación, el clasificador Naïve Bayes estima la probabilidad de que un dato pertenezca a una determinada clase o categoría, utilizando la información disponible en los datos de entrenamiento.
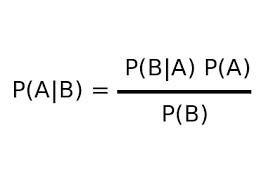
El clasificador Naïve Bayes asume una independencia condicional entre las características de los datos, permitiendo ser rápido y eficaz en su interpretación. Se basa en el cálculo de la probabilidad condicional de que una instancia pertenezca a una clase determinada, utilizando la información de las características observadas. Después, selecciona la clase con la mayor probabilidad como resultado final.
Se usa en múltiples áreas: en el campo de la clasificación de textos, en la detección de spam o correos electrónicos no deseados, en ciertos análisis para redes sociales, la clasificación de imágenes, la recomendación de productos, etc. Al igual que los Árboles de decisión también se aplica en la detección de fraudes. Su simplicidad y eficacia lo convierten en una opción popular para muchos problemas de clasificación.
Ordinary Least Squares Regression
Es un método que busca crear la mejor línea recta ajustándose a los datos proporcionados. Para ello se sirve de una función de pérdida que minimiza la suma de los errores al cuadrado entre los valores observados y los valores predichos por el modelo. Si has trabajado con la estadística es probable que te suene este concepto. Consiste en encontrar los coeficientes que minimizan esta función y que ofrecen la mejor estimación de los parámetros del modelo.
Esta función se utiliza en numerosas materias. Se aplica en estudios económicos, ciencias sociales, análisis financiero y muchas otras áreas donde se busca comprender y predecir relaciones entre variables. También es muy útil para modelar relaciones lineales en problemas de predicción y pronóstico, como la estimación de ventas, el análisis de tendencias y la evaluación del rendimiento.
Logistic Regression
La Regresión Logística es un modelo estadístico que nos ayuda a predecir el acontecimiento de un evento binario. Se basa en la función logística, que mapea una combinación lineal de variables independientes a un valor entre 0 y 1. Esta función logística transforma la salida en una probabilidad, lo que permite realizar una clasificación.
Utiliza un enfoque de máxima proximidad para ajustar los coeficientes del modelo y encontrar el mejor cálculo de los parámetros. Una vez ajustada la función, se define un umbral para seleccionar la categoría a la que pertenece el elemento.
La Regresión Logística tiene una amplia gama de aplicaciones en el campo del machine learning. Se utiliza en problemas de clasificación binaria, como la detección de spam, el diagnóstico médico, la predicción de la probabilidad de impago de un préstamo y la detección de enfermedades. También se puede utilizar en problemas de clasificación multiclase, donde se deben clasificar eventos en más de dos categorías.
Support Vector Machines
El algoritmo de Support Vector Machines SVM, busca hallar un hiperplano óptimo que distinga los datos de entrenamiento en diferentes tipos. Para hacerlo, mapea los datos de entrada en un espacio de mayor dimensión utilizando funciones kernel. Luego, encuentra el hiperplano que maximiza la separación entre las clases, minimizando al mismo tiempo el error de clasificación.
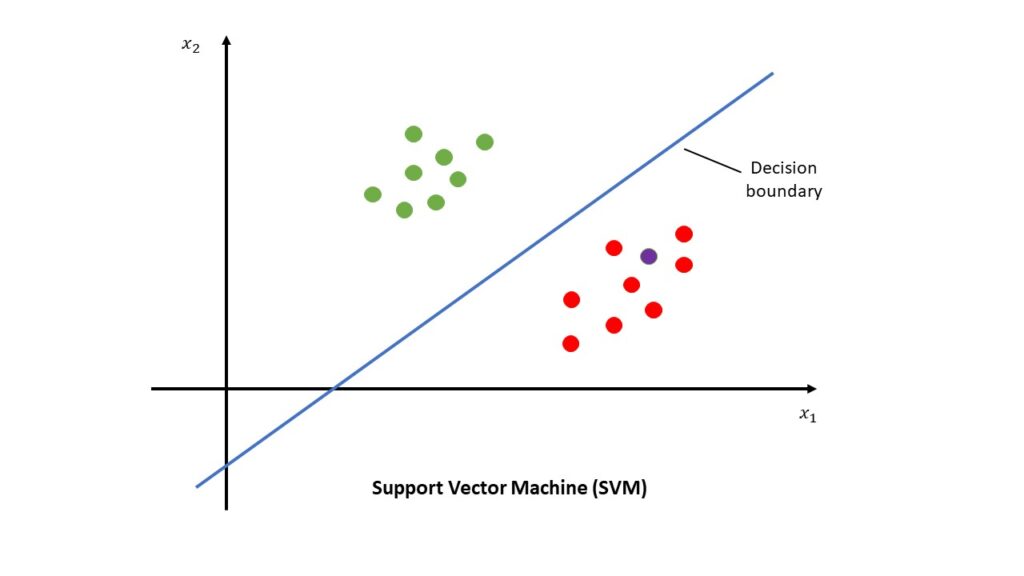
Las Máquinas de Vectores de Soporte aportan múltiples funcionalidades en el campo del aprendizaje automático. Se utilizan en problemas de clasificación, como la clasificación de imágenes y el reconocimiento de voz. También se aplican en problemas de regresión, donde se busca predecir valores continuos en función de variables independientes.
Métodos Ensemble
Los métodos Ensemble son técnicas de aprendizaje automático. Combinan múltiples modelos para llegar a mejores resultados predictivos. Estos métodos aprovechan la diversidad y la combinación de varios modelos individuales para mejorar la precisión y la robustez de las predicciones.
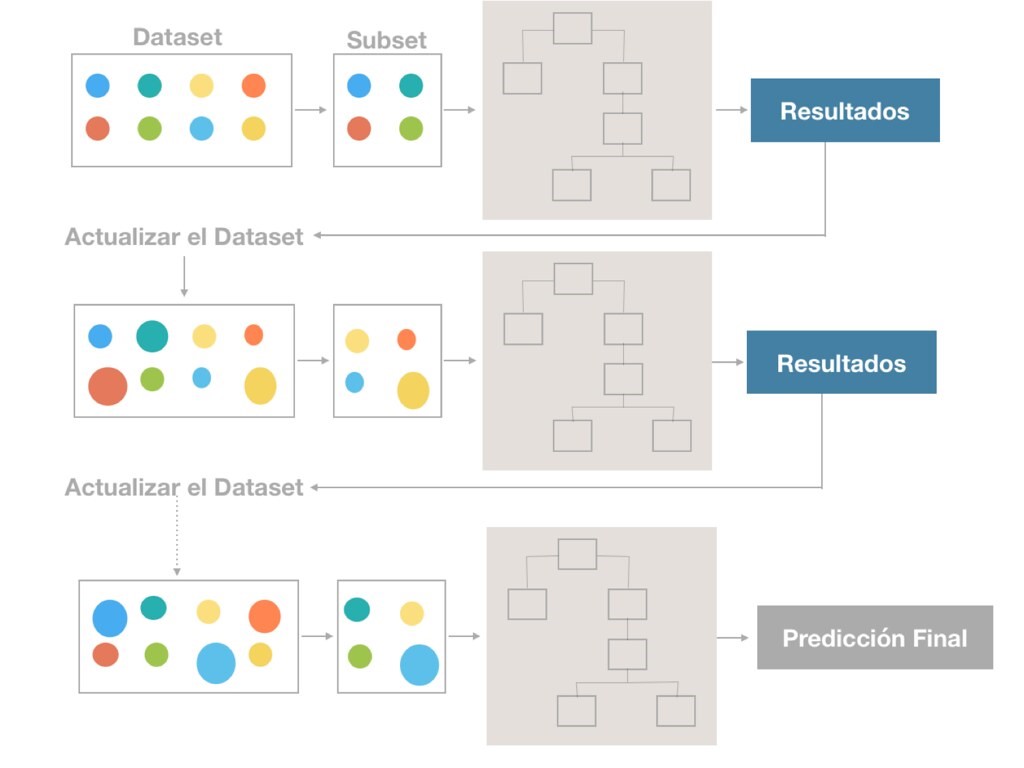
Estos modelos individuales pueden ser del mismo tipo o de tipos diferentes. Al combinar las predicciones de los modelos, se busca obtener una predicción más precisa y generalizable que la que podría obtenerse con un solo modelo.
Algoritmos Clustering
Los algoritmos de Clustering son técnicas utilizadas en el campo del aprendizaje automático para agrupar conjuntos de datos similares en clústeres o grupos. Estos algoritmos buscan encontrar patrones y estructuras intrínsecas en los datos sin la necesidad de etiquetas o categorías predefinidas. Veamos cómo funcionan y algunas de sus aplicaciones.
Evaluación: Se evalúa la calidad de los clústeres formados utilizando métricas como la varianza intra-cluster o la separación inter-cluster.
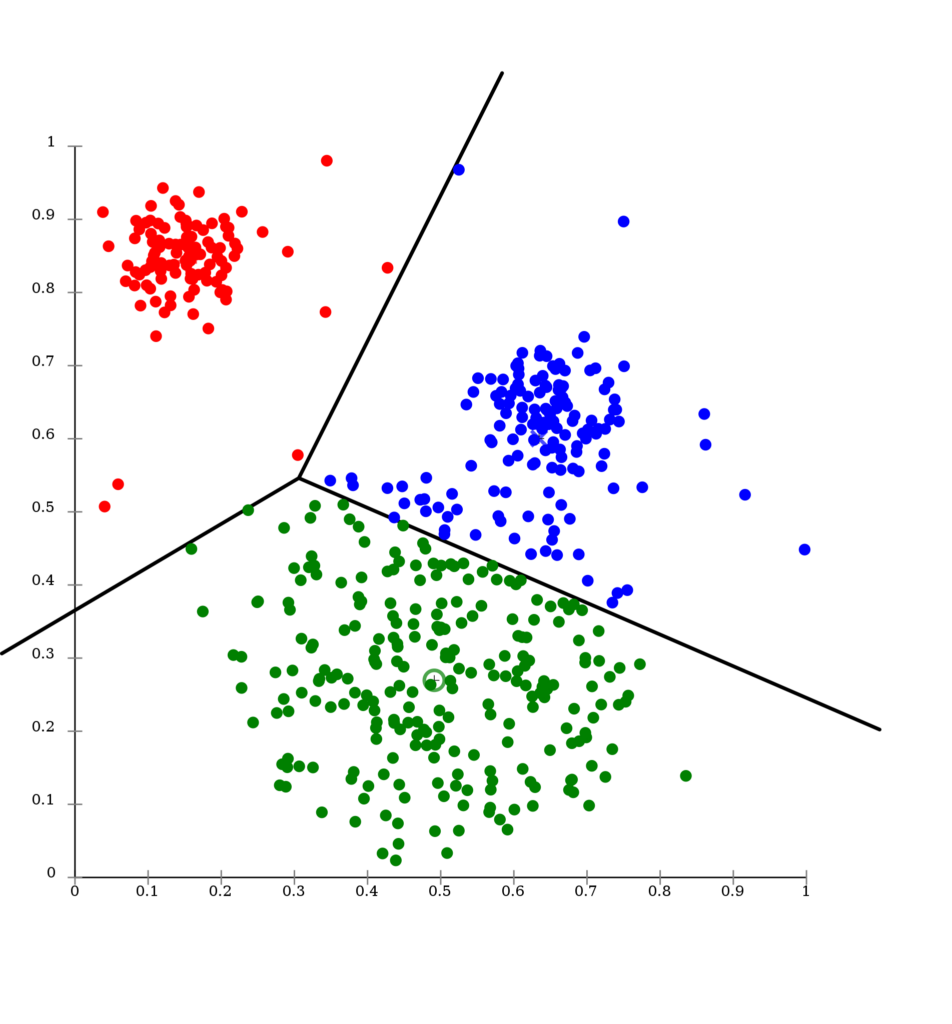
Tienen múltiples aplicaciones en diferentes campos como la segmentación de clientes, análisis de redes sociales, agrupación de documentos, reconocimiento de patrones, segmentación de imágenes o análisis de datos científicos.
Análisis de Componentes Principales
El análisis de componentes principales (ACP) es una técnica estadística utilizada para reducir la dimensionalidad de un conjunto de datos, al tiempo que conserva la mayor cantidad de información posible.
A través del ACP, se busca encontrar las direcciones de máxima varianza en los datos y proyectarlos en un nuevo espacio dimensional más reducido. Veamos cómo funciona y algunas de sus aplicaciones:
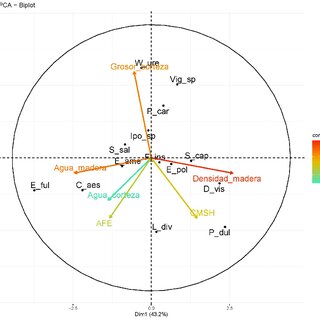
La Aplicación de Componentes principales ofrece muchas aplicaciones como la reducción de dimensionalidad para reducir la cantidad de variables, manteniendo la mayor parte de la información. También sirve para el análisis de datos financieros, reconocimiento de patrones, estudio de datos genéticos en el campo de la biología, segmentación de clientes, o la compresión de imágenes, por ejemplo.
Singular Value Decomposition
La Descomposición en Valores Singulares (DVS) es una función matemática utilizada para deshacer una matriz en componentes más simples y significativos. Ampliamente utilizada en el campo del álgebra lineal y el procesamiento de datos.
La DVS descompone una matriz en tres componentes principales: vectores singulares izquierdos, valores singulares y vectores singulares derechos. Esta descomposición permite analizar y comprender las propiedades fundamentales de una matriz y utilizar esta información en diversas aplicaciones.
Se aplica para la compresión de datos, análisis de imágenes, reconstrucción de datos faltantes o análisis de datos científicos.
Como hemos visto los algoritmos de machine learning son muy útiles para desarrollar herramientas de predicción, organizar información y obtener resultados más sencillos para trabajar. Esto permite a las empresas de muchos sectores subir un nivel en la calidad de su trabajo o en la mejora de resultados.
Si quieres descubrir más sobre el machine learning, ponte en contacto con nosotros y únete a nuestra comunidad.