En el campo del machine learning, entender cómo los modelos toman decisiones es crucial para la interpretación y la confianza en los resultados. SHAP (SHapley Additive exPlanations) es una herramienta poderosa que nos permite descomponer la predicción de un modelo y entender la contribución de cada variable en esa predicción.
¿Qué es SHAP?
SHAP se basa en la teoría de juegos y asigna un valor de importancia a cada feature para cada predicción individual. Esto nos permite no solo entender la importancia general de cada variable, sino también cómo cada valor específico de una variable afecta la predicción del modelo.
Para profundizar en su funcionamiento, vamos a explorar un caso práctico paso a paso. En este ejemplo práctico, hemos incluido gráficos que proporcionan una visión general del impacto de las variables. Sin embargo, estos son solo algunos de los gráficos disponibles; existen otros sobre los que se puede tener información más detallada. Pero en esta introducción a SHAP, nos hemos centrado en lo esencial para mantener la claridad y evitar confusiones.
Implementación con un caso práctico
En este ejemplo vamos a ver cómo SHAP (SHapley Additive exPlanations) nos ayuda a interpretar y explicar las decisiones de un modelo de machine learning aplicado al conjunto de datos de cáncer de mama. Utilizaremos un modelo XGBoost entrenado para predecir si un tumor es maligno o benigno basándose en características clínicas. Es un ejemplo bastante simple de predicción. No hemos utilizado técnicas como k-fold cross-validation, selección de variables u optimización de hiperparámetros, entre otras. Si tienes curiosidad por cómo se puede mejorar la precisión de las predicciones, te invitamos a visitar nuestro blog post dedicado a este tema.
¡IMPORTANTE!
SHAP es una herramienta relativamente nueva que generalmente no está preinstalada. Para instalarla, puedes ejecutar el siguiente comando: !pip install shap. Si estás utilizando Google Colab, este comando será suficiente. En otros entornos o lenguajes de programación, la sintaxis puede variar ligeramente.
import pandas as pd
import shap
import xgboost
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# Cargar el dataset de cáncer de mama desde scikit-learn
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# Dividir el dataset en entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Entrenar un modelo XGBoost
model = xgboost.XGBClassifier(objective="binary:logistic", random_state=42)
model.fit(X_train, y_train)
# Crear un objeto Explainer de SHAP usando TreeExplainer
explainer = shap.TreeExplainer(model)
# Calcular los valores SHAP para el conjunto de prueba
shap_values = explainer.shap_values(X_test) Explicación e interpretación de las funciones de SHAP
1. implementación
1. shap.TreeExplainer(model)
Esta función crea un objeto Explainer de SHAP específicamente para modelos basados en árboles (como XGBoost). Es fundamental para calcular los valores SHAP y entender cómo cada variable contribuye a las predicciones del modelo.
import shap
explainer = shap.TreeExplainer(model)Interpretación:
- model: Es el modelo entrenado del cual deseas obtener explicaciones. En este caso, utilizamos un modelo XGBoost.
2. explainer.shap_values(X_test)
Después de crear el objeto Explainer, puedes calcular los valores SHAP para un conjunto de datos de prueba específico (X_test).
shap_values = explainer.shap_values(X_test) Interpretación:
- X_test: Son los datos de prueba para los cuales deseas explicar las predicciones del modelo. SHAP calculará los valores SHAP para cada instancia en X_test.
2. Interpretación de los valores SHAP
Cuando se utiliza SHAP con un modelo de clasificación binaria, los valores SHAP nos proporcionan una explicación de cómo cada característica contribuye a la probabilidad de que una instancia pertenezca a una clase específica. Aquí te explico cómo puedes interpretar esto:
- Valores SHAP positivos y negativos:
- Un valor SHAP positivo para una característica indica que esta característica está contribuyendo positivamente a la probabilidad de que la instancia pertenezca a la clase positiva (1 en una clasificación binaria).
- Un valor SHAP negativo indica que la característica está contribuyendo negativamente a la probabilidad de que la instancia pertenezca a la clase positiva, lo que puede aumentar la probabilidad de que pertenezca a la clase negativa (0 en una clasificación binaria).
- Impacto de las variables:
- Para entender cómo una variable específica ha impactado en la decisión del clasificador, puedes utilizar diferentes gráficos proporcionados por SHAP, como el summary plot y el dependence plot.
3. Gráficos de SHAP
SHAP genera varios tipos de gráficos que nos ayudan a interpretar cómo afectan las variables individuales a las predicciones del modelo:
a) Resumen de importancia de Variables
El gráfico de resumen de importancia nos muestra la importancia de cada variable en las predicciones globales del modelo. Cada punto en el gráfico representa una observación, y su posición y color indican cómo cada variable contribuye a la predicción.
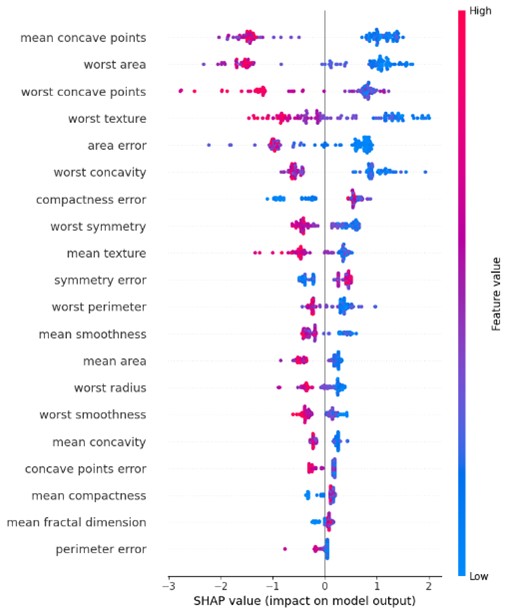
# Mostrar el summary plot
shap.summary_plot(shap_values, X_test, feature_names=X.columns) Nos ayuda a entender qué variables tienen el mayor impacto en las predicciones del modelo en general.
b) Dependencia Parcial
El gráfico de dependencia parcial nos muestra cómo cambia la predicción del modelo al variar el valor de una variable específica mientras se mantienen constantes las demás variables. Esto nos ayuda a entender la relación entre una variable y la predicción del modelo.
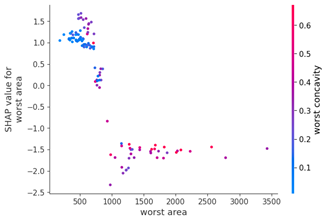
# Mostrar el gráfico de dependencia parcial para la variable 'worst area'
feature_index = X.columns.get_loc('worst ares')
shap.dependence_plot(feature_index, shap_values, X_test, feature_names=X.columns) Es útil para explorar cómo una variable afecta las predicciones del modelo en diferentes rangos de valores.
c) Impacto Indvidual
El gráfico de impacto individual nos permite explorar cómo cada variable contribuye a la predicción para una observación específica. Esto es útil para entender por qué el modelo toma decisiones particulares para casos individuales.
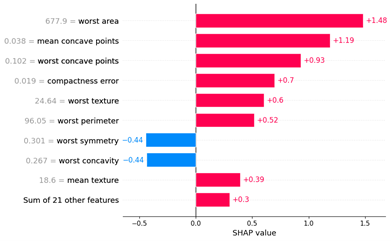
# Mostrar el gráfico de barras para los valores SHAP de la primera instancia en X_test
shap.plots.bar(shap.Explanation(values=shap_values[0], base_values=explainer.expected_value, data=X_test.iloc[0], feature_names=X.columns)) Este tipo de gráfico proporciona una explicación específica sobre cómo cada variable influye en la predicción para una instancia particular.
Conclusiones
SHAP es una herramienta fundamental para entender y explicar las decisiones de los modelos de machine learning como Random Forest y SVM. Permite una interpretación intuitiva y detallada de cómo las variables afectan las predicciones, lo que es crucial tanto para científicos de datos como para stakeholders no técnicos. Al utilizar los gráficos generados por SHAP, podemos mejorar nuestra comprensión del modelo y construir confianza en su uso y aplicaciones prácticas.
Recursos
En este colab notebook SHAP te dejamos el código que hemos utilizado en el ejemplo para que lo tengas como ejemplo o interactúes intentado entender la herramienta. Además te dejamos la libreria de SHAP y otro ejemplo de implementación de SHAP SHAP demo.